

As AI technology advances quickly, you will discover energizing commerce openings. If you are a apprentice, plunging into AI can open entryways to making cutting-edge models and innovations. To successfully create and work with these AI systems, you must learn and get a handle on the key steps like tokenization and implanting. Both are the building pieces in taking care of and translating information for AI models but have contrasts in their capacities. This article will offer assistance you ace tokenization and token embeddings and how they vary. With this information, you’ll be well-equipped to construct AI-driven applications such as chatbots, generative AI colleagues, language translators, and recommender systems.
What Is Tokenization?
Tokenization is the prepare of taking the input content and apportioning it into little, secure, sensible units called tokens. These units can be words, expressions, sub-words, punctuation marks, or characters. According to OpenAI, one token is almost four characters and ¾ words in English. This demonstrates that 100 tokens are roughly rise to to 75 words.
Tokenization is the vital step in Normal Dialect Handling (NLP). Amid this handle, you are planning your input content in a organize that makes more sense to AI models without losing its setting. Once tokenized, your AI frameworks can analyze and translate human dialect efficiently.
Let’s take a see at the key steps to perform tokenization:
Step 1: Normalization
An beginning step in which you require to change over the input content to lowercase utilizing NLP devices to guarantee consistency. You can at that point strip out superfluous accentuation marks and supplant or expel uncommon characters like emojis or hashtags.
Step 2: Splitting
You can break down your content into tokens utilizing any one of the taking after approaches:
Word Tokenization
The word tokenization strategy is appropriate for conventional dialect models like n-gram. It permits you to part the input content into person words.
Consider the sentence: “The chatbots are beneficial.”
In the word-tokenization approach, this sentence would be tokenized as:
[“The”, “chatbots”, “are”, “beneficial”]
Sub-word Tokenization
Modern language models like GPT-3.5, GPT-4, and BERT utilize a sub-word tokenization approach. This approach breaks down content into littler units than words, which makes a difference handle a broader run of lexicon and complex paragraphs.
Consider the sentence: “Generative AI Colleagues are Beneficial”
In the sub-word tokenization approach, the sentences can be part as:
[“Gener”, “ative”, “AI”, “Assist”, “ants”, “are”, “Benef”, “icial”]
Here, you see eight person tokens. If you were utilizing word tokenization, there would be as it were five tokens.
Character Tokenization
Character tokenization is commonly utilized for systems like spell checkers that require fine-grained examination. It empowers you to segment the entirety content into an cluster of single characters.
Consider the sentence: “I like Cats.”
The character-based tokenization would part the sentence into the taking after tokens:
[“I”, “ “, “l”, “i”, “k”, “e”, “ “, “C”, “a”, “t”, “s”]
Step 3: Mapping
In this step, you must relegate each token a one of a kind identifier and include it to a pre-defined vocabulary.
Step 4: Adding Special Tokens
You can include the taking after uncommon tokens amid tokenization to offer assistance the show get it the structure and setting of the input data.
CLS
CLS is a classification token included at the starting of each input grouping. After the content passes through the show, the yield vector comparing to this token can be utilized to foresee the whole input.
SEP
A separator token that makes a difference you recognize different fragments of content inside the same input. It is valuable in tasks like question-answering or sentence-pair classification.
An outline of the tokenization handle is given below:
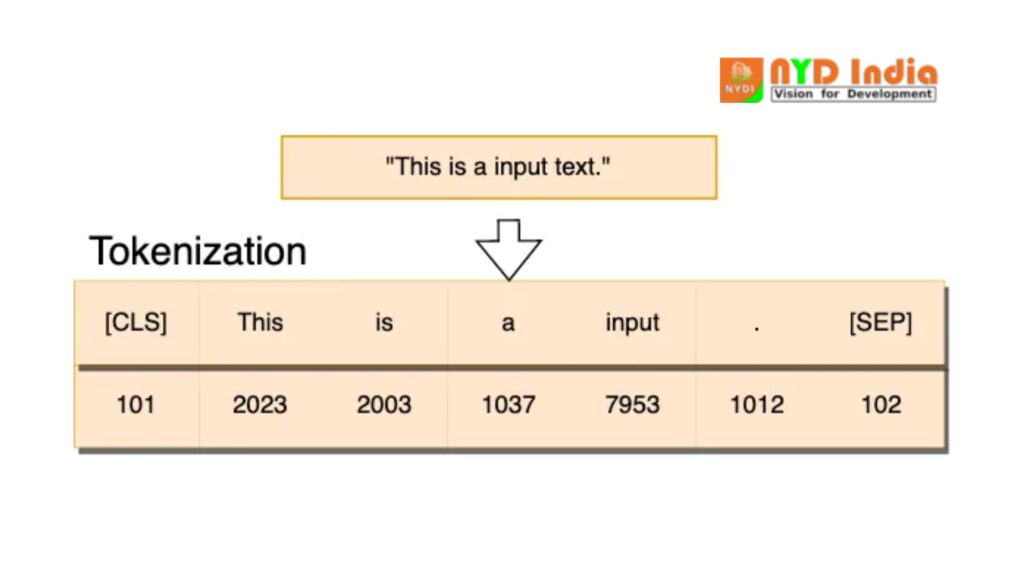
Types of Tokenization
Word-Level Tokenization-Each word is treated as a single token. This approach works well for dialects with clear word boundaries (e.g., English). Be that as it may, it battles with out-of-vocabulary (OOV) words and dialects like Chinese, where boundaries aren’t continuously clear.
Subword Tokenization:Well known strategies like Byte Combine Encoding (BPE) and WordPiece part words into subwords. This approach permits the show to handle uncommon or concealed words by combining regularly happening subword units.
Character-Level Tokenization:This strategy breaks down content into person characters. It’s strong against Out of Lexicon (OOV) words but comes about in long groupings, making it computationally costly.
What are Embeddings?
Embedding is a prepare of speaking to the tokens as continuous vectors in a high-dimensional space where comparable tokens have comparative vector representations. These vectors, too known as embeddings, offer assistance AI/ML models capture the semantic meaning of the tokens and their connections in the input text.
To make these embeddings, you can utilize machine learning calculations such as Word2Vec or GloVe. The coming about embeddings are organized in a lattice, where each push compares to the vector representation of a particular token from a pre-defined vocabulary.
For occurrence, if a lexicon comprises of 10,000 tokens and each implanting has 300 measurements, the implanting framework will be a 10,000 x 300 matrix.
Here are the steps to perform the inserting prepare with an example:
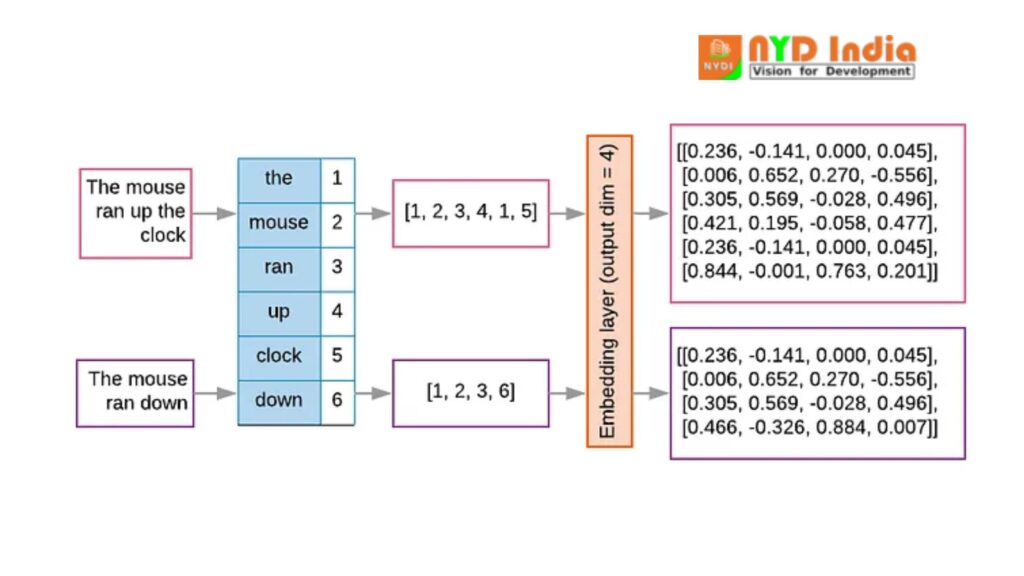
Step 1: Tokenization
In the over illustration, there are two input texts:
Text 1: “The mouse ran up the clock”
Text 2: “The mouse ran down”
In the tokenization handle, you can part up each input content into person tokens. At that point, include each special token to a vocabulary list with an index.
Step 2: Generating Output Vectors
Once tokenized, you will get one-dimensional yield vectors as follows:
For Text 1, the token lists are spoken to as the one-dimensional vector: [1,2,3,4,1,5].
For Text 2, the records are [1,2,3,6].
These records are utilized to recognize the comparing embeddings in the embedding matrix.
Step 3: Creating an Embedding Matrix
The embedding network is the principal component in speaking to tokens as vectors. Each push of the matrix compares to the vector representation of a particular token.
In the given case, the measurement of the vectors is four. So, the embeddings for the yield vector [1,2,3,4,1,5] are as follows:
For list 1: [0.236, -0.141, 0.000, 0.045].
For record 2: [0.006, 0.652, 0.270, -0.556].
Similarly, the inserting framework will contain vector representations for all other four files in the yield vector.
The same prepare applies in the moment yield vector [1,2,3,6], which contrasts from the to begin with vector as it were in the final index.
Step 4: Applying Embeddings
When an AI or ML system forms the content, it recovers the embeddings from the network. This permits the show to get it the setting and meaning of the tokens based on their vector representations.
Tokenization vs. Embeddings
Let’s take a look at the key differences between tokenization and embeddings:
| Parameters | Tokenization | Embedding |
| Definition | Process of converting the large text into separate words, subwords, or characters, known as tokens. | Process of mapping tokens into dense, continuous vector representations. |
| Use | Preprocessing the text into manageable units. | Capturing the semantic meaning of tokens in a form that models can analyze and interpret. |
| Output | A sequence of tokens with an index value. | A sequence of fixed-size vector representations. |
| Example | “Machine Learning” can be tokenized as [“Machine”, “Learning”] | [“Machine”, “Learning”] can be represented as [embedding1, embedding2], where each embedding corresponds to vector representations of a specific token. |
| Granularity | Granularity refers to the highest number of tokens. For character-level tokenization, granularity is very fine, with each character as a token. For word-level, granularity is coarser than character-level, with each word as a token. For subword-level, it is intermediate, where words are split into smaller meaningful units. | Granularity refers to the level of detail at which the tokens are represented in an embedding matrix. Higher granularity indicates more detailed representations, while lower granularity involves more abstract token embeddings. |
| Language Dependency | Might differ across various languages because of the different token structures. | Language-independent once the tokenization is done, but embeddings grasp language semantics. |
| Data Requirement | Needs a pre-defined vocabulary from the training dataset | Needs pre-trained models or training datasets to learn embeddings |
| Tools Stack | Tokenizers such as Byte Pair Encoding, SentencePiece, or WordPiece | Embedding models such as GloVe, BERT, Word2Vec, DeBERTa |
| Common Libraries | spaCy, nltk, and transformers | torch.nn.Embedding, gensim, and transformers |
Leveraging Airbyte for Efficient Tokenization and Embedding in AI Modeling
AI models like LLMs (Large Language Models) are prepared on vast sums of information, enabling them to reply a wide extend of questions over different themes. In any case, when it comes to extricating data from restrictive information, LLMs can be constrained and lead to mistakes. In such cases, consider leveraging Airbyte, a no-code information integration and replication platform.
Airbyte permits you to coordinated information from all sources into a target framework utilizing its 350+ pre-built connectors. If no existing connector meets your needs, you can construct a modern one with fundamental coding information through its CDK feature.
In expansion, Airbyte supports RAG-based changes, like LangChain-powered chunkings and OpenAI-enabled embeddings. This will disentangle the information integration handle in a single step and empower LLMs to deliver more precise, pertinent, and up-to-date text.
Here are a few key highlights of Airbyte:
Modern Generative AI workflows: Airbyte makes a difference you streamline AI forms by stacking unstructured information into vector database goals, such as Pinecone, Milvus, and Weaviate. Vector goals offer effective closeness looks and relevance-based recovery, which is accommodating for information analysis.
Efficient Information Change: With dbt integration, you can make and actualize custom changes inside your information pipelines.
Developer-Friendly Pipelines: Airbyte gives an open-source, developer-friendly Python library, PyAirbyte. It permits you to programmatically interface with Airbyte connectors to extricate information from changed sources in your Python workflows.
Data Synchronization: Airbyte offers a CDC highlight to track the most recent upgrades in the source frameworks and reproduce them in your target framework. This guarantees that information in the goal remains adjusted with the source database.
Open-Source: Airbyte gives an open-source adaptation that makes a difference you send your Airbyte occurrence locally utilizing Docker or on a virtual machine. This version permits you to use all the built-in connectors, pattern engendering, and low-code/no-code connector builder features.
Data Security: Airbyte offers tall security amid integration with TLS and HTTPS encryption, SSH tunneling, role-based get to controls, and credential administration. It moreover follows to ISO 27001 and SOC 2 Sort II administrative compliance for a secure process.
Why Tokenization Matters
Tokenization bridges the hole between normal language and machine learning models. Since models can’t directly get it raw content, tokenization serves as the to begin with step in changing over content into a arrangement of discrete components (tokens) that a show can process.
Token IDs: After tokenization, each token is mapped to a special ID in the model’s vocabulary. For illustration, the token “cat” might be mapped to the ID 345, whereas “tangle” might be mapped to 563. This numeric representation is what the show really works with.
Challenges in Tokenization
Handling Special Characters: Emojis, punctuation, and numbers can complicate tokenization. Tokenizers must choose whether to treat them as isolated tokens or combine them with encompassing text.
Multilingual Texts:For models prepared on multiple dialects, tokenization must adjust to diverse scripts, grammar rules, and word structures, which can shift broadly over languages.
How Embeddings Work
Embeddings are learned amid the preparing prepare of dialect models. They are initialized randomly, and through preparing, the show learns to alter these vectors so that words with comparative meanings are put closer together in the vector space.
Popular embedding strategies include:
Word2Vec:Trains word embeddings based on the setting in which words show up. It employments two strategies: Skip-gram and Continuous Bag of Words (CBOW).
GloVe: Captures worldwide word co-occurrence insights to learn word embeddings, emphasizing both nearby and worldwide data in text.
BERT embeddings:Relevant embeddings where a word’s representation changes based on its encompassing setting. For occasion, “bank” in “stream bank” and “bank” in “cash bank” would have distinctive embeddings.
Dimensions of Embeddings
The dimensionality of embeddings changes by demonstrate, regularly extending from 50 to 1,000 measurements. For occasion, OpenAI’s GPT-3 demonstrate employments 12,288-dimensional embeddings for its biggest demonstrate. More measurements permit the demonstrate to capture wealthier and more complex connections, but they moreover increment computational costs.
Why Embeddings are Important
Embeddings give a way to speak to words (and other tokens) in a way that jam semantic meaning. By changing over discrete tokens into thick vectors, embeddings permit models to:
Understand Synonyms and Relationships:Comparable words are put near to each other in vector space, empowering the show to get it equivalent words and related concepts.
Generalize Across Contexts:: Models with embeddings can generalize superior to modern settings and capture nuanced implications of words depending on their usage.
Challenges with Embeddings
Understand Synonyms and Relationships:Words with numerous implications (e.g., “bank”) can cause issues if a demonstrate employments inactive embeddings. Relevant embeddings, like those from BERT, address this by permitting words to have distinctive embeddings based on their context.
Generalize Across Contexts:Whereas high-dimensional embeddings capture more points of interest, they are computationally costly. On the other hand, low-dimensional embeddings may lose vital semantic information.
How Embeddings and Tokenization Work Together
Tokenization and implanting are two steps in the broader pipeline of normal dialect preparing. After tokenizing the content, the demonstrate changes over the tokens into embeddings, which are at that point encouraged into ensuing layers of the demonstrate for encourage preparing, such as self-attention layers in transformers.
In advanced LLMs like GPT-4 and BERT, tokenization is more often than not subword-based (like WordPiece), which guarantees that indeed uncommon or obscure words can be part into sensible chunks. Once tokenized, the embeddings of these tokens are learned and refined amid training.
Let’s illustrate this with an example:
Input: “Counterfeit insights is the future.”
Tokenized Output: [“Artificial”, “intelligence”, “is”, “the”, “future”, “.”]
Each token is then mapped to an embedding, such as:
Artificial = [0.2, 0.1, -0.7, …]
intelligence = [-0.3, 0.5, 0.9, …]
These embeddings serve as inputs to the demonstrate for assignments like dialect era, classification, or translation.
Conclusion
Embeddings and tokenization are at the center of how LLMs get it and handle dialect. Tokenization breaks down content into reasonable units, whereas embeddings speak to those units in a important way in high-dimensional space. Together, they permit machine learning models to capture the complexities of human dialect and perform assignments extending from content era to translation.
Understanding these procedures is fundamental for anybody looking to plunge profound into NLP, as they frame the establishment upon which most dialect models work. Whether you’re building a chatbot, fine-tuning a show, or investigating AI-driven applications, acing embeddings and tokenization is key to leveraging the full control of present day NLP.










