
What is robots.txt? | How a robots.txt file works?
A robots.txt record tells look motor crawlers which URLs the crawler can get to on your location. This is utilized primarily to maintain a strategic distance from over-burdening your location with demands; it is not a instrument for keeping a web page out of Google. To keep a web page out of Google, square ordering with noindex or password-protect the page.
What Is a Robots.txt File?
A robots.txt record is a set of informational for bots. This record is included in the source records of most websites. Robots.txt records are generally planning for overseeing the exercises of great bots like web crawlers, since awful bots aren’t likely to take after the instructions.
Think of a robots.txt record as being like a “Code of Conduct” sign posted on the divider at a exercise center, a bar, or a community center: The sign itself has no control to implement the recorded rules, but “great” supporters will take after the rules, whereas “awful” ones are likely to break them and get themselves banned.
A bot is an computerized computer program that interatomic with websites and applications. There are great bots and awful bots, and one sort of great bot is called a web crawler bot. These bots “creep” webpages and list the substance so that it can appear up in look motor comes about. A robots.txt record makes a difference oversee the exercises of these web crawlers so that they do not exhaust the web server facilitating the site, or file pages that aren’t implied for open view.
How does a robots.txt file work?
A robots.txt record is fair a content record with no HTML markup code (subsequently the .txt expansion). The robots.txt record is facilitated on the web server fair like any other record on the site. In truth, the robots.txt record for any given site can regularly be seen by writing the full URL for the homepage and at that point including /robots.txt, like https://www.cloudflare.com/robots.txt. The record isn’t connected to anyplace else on the location, so clients aren’t likely to bumble upon it, but most web crawler bots will see for this record to begin with some time recently slithering the rest of the site.
While a robots.txt record gives informational for bots, it can’t really implement the informational. A great bot, such as a web crawler or a news bolster bot, will endeavor to visit the robots.txt record to begin with some time recently seeing any other pages on a space, and will take after the enlightening. A terrible bot will either disregard the robots.txt record or will prepare it in arrange to discover the webpages that are forbidden.
A web crawler bot will take after the most particular set of informational in the robots.txt record. If there are conflicting commands in the record, the bot will take after the more granular command.
One imperative thing to note is that all subdomains require their claim robots.txt record. For occurrence, whereas www.cloudflare.com has its claim record, all the Cloudflare subdomains (blog.cloudflare.com, community.cloudflare.com, etc.) require their possess as well.
What protocols are used in a robots.txt file?
In organizing, a convention is a organize for giving enlightening or commands. Robots.txt records utilize a couple of distinctive conventions. The fundamental convention is called the Robots Prohibition Convention. This is a way to tell bots which webpages and assets to maintain a strategic distance from. Informational designed for this convention are included in the robots.txt file.
The other convention utilized for robots.txt records is the Sitemaps convention. This can be considered a robots incorporation convention. Sitemaps appear a web crawler which pages they can creep. This makes a difference guarantee that a crawler bot won’t miss any critical pages.
Example of a robots.txt file
Here’s the robots.txt file for www.cloudflare.com:
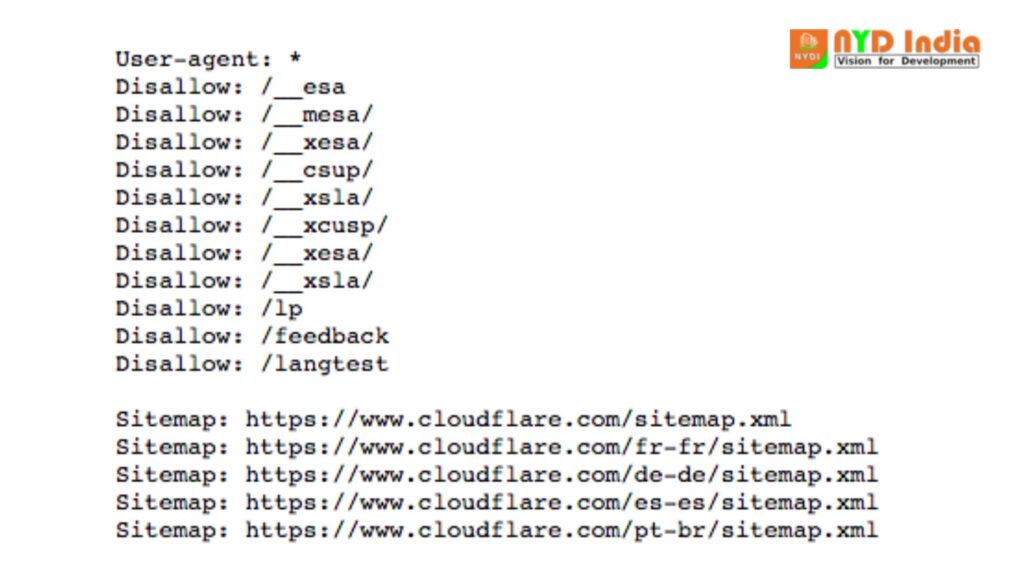
What is a user agent? What does ‘User-agent: *’ mean?
Any individual or program dynamic on the Web will have a “client operator,” or an relegated title. For human clients, this incorporates data like the browser sort and the working framework form but no individual data; it makes a difference websites appear substance that’s congruous with the user’s framework. For bots, the client operator (hypothetically) makes a difference site chairmen know what kind of bots are slithering the site.
In a robots.txt record, site directors are able to give particular enlightening for particular bots by composing distinctive enlightening for bot client specialists. For occasion, if an director needs a certain page to appear up in Google look comes about but not Bing looks, they might incorporate two sets of commands in the robots.txt record: one set gone before by “User-agent: Bingbot” and one set gone before by “User-agent: Googlebot”.
In the illustration over, Cloudflare has included “User-agent: *” in the robots.txt record. The mark speaks to a “wild card” client specialist, and it implies the informational apply to each bot, not any particular bot.
Common look motor bot client operator names include:
Googlebot
Googlebot-Image (for images)
Googlebot-News (for news)
Googlebot-Video (for video)
Bingbot
MSNBot-Media (for pictures and video)
Baiduspider
How do ‘Disallow’ commands work in a robots.txt file?
The Forbid command is the most common in the robots avoidance convention. It tells bots not to get to the webpage or set of webpages that come after the command. Refused pages aren’t essentially “covered up” – they fair aren’t valuable for the normal Google or Bing client, so they aren’t appeared to them. Most of the time, a client on the site can still explore to these pages if they know where to discover them.
The Forbid command can be utilized in a number of ways, a few of which are shown in the case above.
Block one file (in other words, one particular webpage)
As an example, if Cloudflare wished to block bots from crawling our “What is a bot?” article, such a command would be written as follows:
Disallow: /learning/bots/what-is-a-bot/After the “disallow” command, the part of the URL of the webpage that comes after the homepage – in this case, “www.cloudflare.com” – is included. With this command in place, good bots won’t access https://www.cloudflare.com/learning/bots/what-is-a-bot/, and the page won’t show up in search engine results.
Block one directory
Sometimes it’s more efficient to block several pages at once, instead of listing them all individually. If they are all in the same section of the website, a robots.txt file can just block the directory that contains them.
Disallow: /__mesa/This means that all pages contained within the __mesa directory shouldn’t be crawled.
Allow full access
Such a command would look as follows:
Disallow:This tells bots that they can browse the entire website, because nothing is disallowed
Hide the entire website from bots
Disallow: /The “/” here represents the “root” in a website’s hierarchy, or the page that all the other pages branch out from, so it includes the homepage and all the pages linked from it. With this command, search engine bots can’t crawl the website at all.
What other commands are part of the Robots Exclusion Protocol?
Allow: Fair as one might anticipate, the “Permit” command tells bots they are permitted to get to a certain webpage or catalog. This command makes it conceivable to permit bots to reach one specific webpage, whereas refusing the rest of the webpages in the record. Not all look motors recognize this command.
Crawl-delay: The creep delay command is implied to halt look motor creepy crawly bots from overtaxing a server. It permits chairmen to indicate how long the bot ought to hold up between each ask, in milliseconds. Here’s an case of a Crawl-delay command to hold up 8 milliseconds:
Crawl-delay: 8What is the Sitemaps protocol? Why is it included in robots.txt?
The Sitemaps convention makes a difference bots know what to incorporate in their slithering of a website.
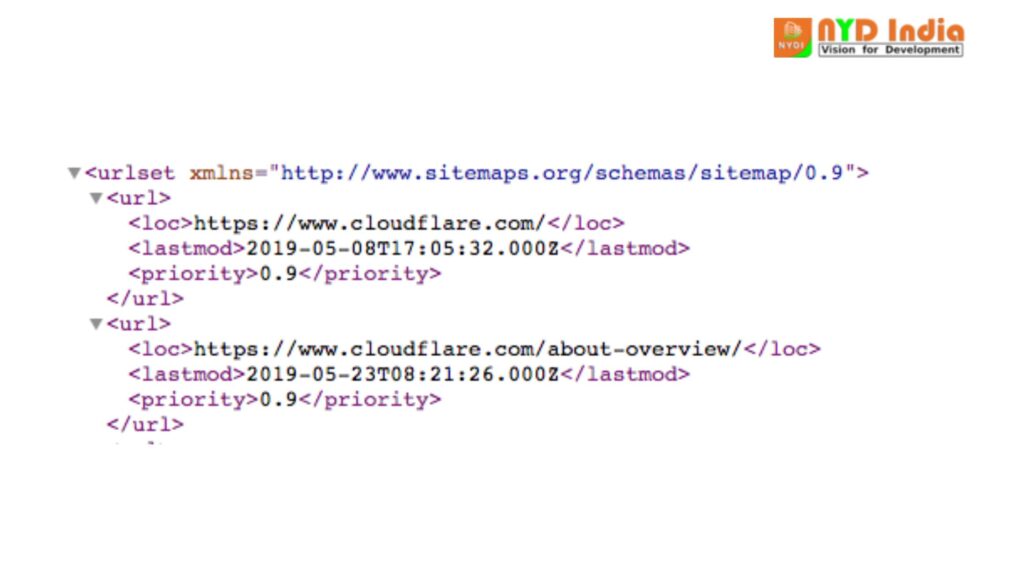
A sitemap is an XML record that looks like this:
It’s a machine-readable list of all the pages on a site. Through the Sitemaps convention, joins to these sitemaps can be included in the robots.txt record. The arrange is: “Sitemaps:” taken after by the web address of the XML record. You can see a few cases in the Cloudflare robots.txt record above.
While the Sitemaps convention makes a difference guarantee that web creepy crawly bots do not miss anything as they slither a site, the bots will still take after their normal slithering handle. Sitemaps do not drive crawler bots to prioritize webpages differently.
How does robots.txt relate to bot management?
Managing bots is fundamental for keeping a site or application up and running, since indeed great bot movement can strain an beginning server, abating down or taking down a web property. A well-constructed robots.txt record keeps a site optimized for SEO and keeps great bot movement beneath control.
However, a robots.txt record won’t do much for overseeing noxious bot activity. A bot administration arrangement such as Cloudflare Bot Administration or Super Bot Battle Mode can offer assistance check pernicious bot movement without affecting fundamental bots like web crawlers.
Understand the limitations of a robots.txt file

Before you make or alter a robots.txt record, you ought to know the limits of this URL blocking strategy. Depending on your objectives and circumstance, you might need to consider other instruments to guarantee your URLs are not findable on the web.
1.robots.txt rules may not be backed by all look engines.
The enlightening in robots.txt records cannot uphold crawler behavior to your location; it’s up to the crawler to comply them. Whereas Googlebot and other respectable web crawlers comply the informational in a robots.txt record, other crawlers might not. In this manner, if you need to keep data secure from web crawlers, it’s superior to utilize other blocking strategies, such as password-protecting private records on your server.
2.Different crawlers decipher language structure differently.
Although respectable web crawlers take after the rules in a robots.txt record, each crawler might translate the rules in an unexpected way. You ought to know the legitimate language structure for tending to distinctive web crawlers as a few might not get it certain instructions.
3.A page that’s refused in robots.txt can still be ordered if connected to from other sites.
While Google won’t slither or list the substance blocked by a robots.txt record, we might still discover and record a refused URL if it is connected from other places on the web. As a result, the URL address and, possibly, other freely accessible data such as stay content in joins to the page can still show up in Google look comes about. To legitimately anticipate your URL from showing up in Google look comes about, password-protect the records on your server, utilize the noindex meta tag or reaction header, or evacuate the page entirely.
Importance of robots.txt for SEO and website management

1.A well-configured Robots.txt record offers a few benefits for SEO and site efficiency:
2.Manage slithering needs: Coordinate bots to center on profitable substance whereas skipping copy or unimportant pages.
3.Optimize sitemap utilization: Direct crawlers to the sitemap to guarantee proficient ordering of key directories.
4.Conserve server assets: Diminish pointless bot movement, anticipating intemperate stack on HTTP requests.
5.Protect delicate records: Anticipate crawlers from getting to or ordering secret or non-public TXT files.
6.Enhance SEO methodology: Back way better creep budget assignment and progress site perceivability by centering on the right areas.
Best practices for robots.txt
To guarantee your robots.txt record capacities ideally, take after these best practices:
1.File area issues
Place robots.txt in the root catalog (e.g., www.example.com/robots.txt).
2.Ensure adjust syntax
Validate designing with devices like Google’s Robots Testing Device to dodge errors.
3.Don’t square CSS or JavaScript
Allow get to to assets required for appropriate rendering.
4.Use a sitemap directive
Link your sitemap to direct crawlers to basic content.
5.Monitor crawler behavior
Check server logs or analytics to affirm compliance with your rules.
Meta robot labels are too vital in overseeing SEO and avoiding issues like coincidental noindex mandates.
What is canonicalization?
Canonicalization is the prepare of selecting the agent –canonical– URL of a piece of substance. Subsequently, a canonical URL is the URL of a page that Google chose as the most agent from a set of copy pages. Regularly called deduplication, this prepare makes a difference Google appear as it were one adaptation of the something else copy substance in its look results.
There are numerous reasons why a location may have copy content:
1.Region variations: for illustration, a piece of substance for the USA and the UK, available from distinctive URLs, but basically the same substance in the same language
2.Device variations: for illustration, a page with both a portable and a desktop version
3.Protocol variations: for case, the HTTP and HTTPS forms of a site
4.Site capacities: for illustration, the comes about of sorting and sifting capacities of a category page
5.Accidental variations: for case, the demo form of the location is incidentally cleared out open to crawlers
Some copy substance on a location is typical and it’s not a infringement of Google’s spam approaches. In any case, having the same substance available through numerous distinctive URLs can be a terrible client involvement (for illustration, individuals might ponder which is the right page, and whether there’s a contrast between the two) and it may make it harder for you to track how your substance performs in look results.
How Google indexes and chooses the canonical URL
When Google files a page, it decides the essential substance (or centerpiece) of each page. If Google finds different pages that appear to be the same or the essential substance exceptionally comparative, it chooses the page that, based on the variables (or signals) the ordering prepare collected, is impartially the most total and valuable for look clients, and marks it as canonical. The canonical page will be crept most routinely; copies are slithered less regularly in arrange to diminish the slithering stack on sites.
There are a modest bunch of variables that play a part in canonicalization: whether the page is served over HTTP or HTTPS, diverts, nearness of the URL in a sitemap, and rel=”canonical” interface comments. You can show your inclination to Google utilizing these procedures, but Google may select a distinctive page as canonical than you do, for different reasons. That is, showing a canonical inclination is a imply, not a rule.
Different dialect adaptations of a single page are considered copies as it were if the essential substance is in the same dialect (that is, if as it were the header, footer, and other non-critical content is deciphered, but the body remains the same, at that point the pages are considered to be copies). To learn more around setting up localized locales, see our documentation approximately overseeing multi-lingual and multi-regional sites.
Google employments the canonical page as the fundamental source to assess substance and quality. A Google Look result ordinarily focuses to the canonical page, unless one of the copies is unequivocally way better suited for a look client. For illustration, the look result will likely point to the portable page if the client is on a versatile gadget, indeed if the desktop page is the canonical.
Common mistakes to avoid Robert.txt
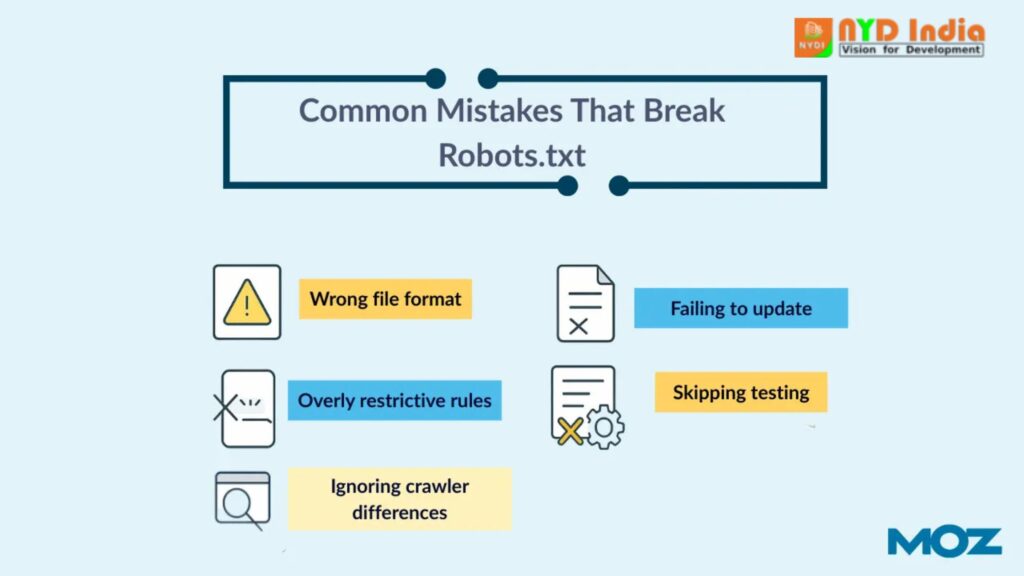
Robots.txt files are simple but prone to mistakes that can negatively impact your website’s visibility or functionality:
1.Wrong record format
2.Save as a plain content record with UTF-8 encoding to guarantee readability.
3.Overly prohibitive rules
4.Avoid blocking basic catalogs or pages required for SEO.
5.Skipping testing
6.Regularly test your robots.txt with apparatuses like Google’s analyzer to guarantee functionality.
7.Ignoring crawler differences
8.Tailor rules to the behavior of particular client agents.
9.Failing to update
10.Revise robots.txt as your site structure changes.
Can I block AI bots with robots.txt?
Yes, robots.txt can be utilized to prohibit AI bots like ClaudeBot, GPTbot, and PerplexityBot. Numerous news and distribution websites have as of now blocked AI bots. For occasion, inquire about by Moz’s Senior Look Researcher, Tom Capper appears that GPTbot is the most blocked bot. In any case, whether blocking AI bots is the right move for your location and whether this will be honored by all AI bots is still beneath audit and subject to discourse.